
Between Excel and AI: Why data becomes a bottleneck in R&D
Everyone in R&D knows the situation: experimental series, formulations, measurement data and evaluations end up in Excel spreadsheets. Colleagues complement their documentation with files stored in folder structures, SharePoint instances or local drives. This becomes a problem as soon as data needs to be reused across projects, compared systematically or analysed over longer periods of time.
The result is familiar: information is scattered across different systems and formats. Responsibilities are unclear, naming conventions inconsistent. Versions are difficult to trace, and relationships between materials, processes and results are lost. Historical data may still exist, but finding it requires considerable effort. Experiments are repeated, development timelines slip, and customers are left waiting.
This is not a theoretical issue. A survey conducted as part of the European Coatings Conference on digitalisation shows how real the problem is: around two thirds of participants stated that their data is difficult to access or barely searchable. A similar proportion cited a lack of standardisation and an excessive number of different systems as major obstacles in their day-to-day work (Fig. 1).

Source: Participants of the European Coatings Conference 2025
The effort required to find relevant information has consequences. It consumes more time than R&D teams can afford. When time is scarce, decisions are made on the basis of incomplete data — or gut feeling. If, in the course of an upcoming generational transition, an experienced employee leaves the company, it is not only their expertise that is lost, but also the associated data.
This situation is not sustainable. Competitive pressure continues to increase, placing equal strain on heads of development and their teams. At the same time, new technologies such as artificial intelligence are entering the picture, promising a way out. However, these technologies can only realise their potential if structured, connected and contextualised data is available.
Under these conditions, how can teams make well-founded decisions and use new technologies in a meaningful way?
What matters today: structuring data, creating context
The answer lies less in individual tools and more in a structured approach to data, processes and AI. Standalone solutions for data acquisition, project management or analysis fall short. Legacy LIMS are too rigid, ELNs too limited. What is missing is an overarching approach that brings order to the complexity of R&D and enables effective data management in R&D.
Material Intelligence describes exactly this organising framework. It is not a single tool, but a structural principle for digital research and development. At its core, Material Intelligence connects three closely interlinked layers: data, workflows and intelligence. Only their interaction creates the foundation for efficient processes and the meaningful use of AI (see figure).
The first layer consists of structured and searchable data — ranging from material properties and formulations to process parameters, measurement data and experimental results. What matters is not the volume of data, but consistency, comparability and clear attribution. Only then can relationships be traced and knowledge reused.
Building on this, workflows are digitally mapped and interconnected. Projects, laboratory processes and experimental sequences are linked; decisions become traceable and handovers clearer. Data does not emerge randomly, but within the context of how it is generated.
The third layer is intelligence. AI does not access isolated data sets, but a consistent data and process environment. This allows it to become a supportive part of everyday work rather than a foreign element.
Without structured data, workflows remain incomplete. Without workflows, data remains fragmented. And without both, AI cannot deliver reliable value. Material Intelligence addresses these dependencies directly and reduces complexity instead of adding to it.
AI in R&D: from promise to practical application
The use of artificial intelligence in industrial R&D is no longer a vision, but increasingly part of everyday practice. At the same time, one thing is becoming clear: success or failure depends not only on data quality, but also on domain context.
In practice, AI assistants are often deployed as generic, context-agnostic tools. They operate on isolated data sets and are unable to take the experimental context of data generation into account. Without the explicit integration of formulation, process and testing information, methods such as machine learning deliver only general results. These fail to meet the specific requirements of research and development, ultimately limiting their value in the R&D environment.
The multi-agent concept of the Co-Engineer follows a different approach. Interaction takes place via a unified user interface, through which queries are passed to a central supervisor agent. This agent breaks the request down into clearly defined subtasks and coordinates their execution by specialised agents, for example for search, analysis or prediction. These agents, in turn, access specific functions of the tool layer, including semantic search, analytical and statistical methods, and predictive modelling.
Predictive AI methods are also used to estimate potential outcomes and trends based on historical data. Bayesian optimisation complements this approach by deliberately proposing new experiments that maximise knowledge gain while reducing experimental effort.
All tools operate on a shared data and infrastructure layer that includes both laboratory data stored in the database and the associated document repositories. This clear separation of responsibilities, combined with the use of domain-specific methods, fundamentally distinguishes the Co-Engineer from generic chatbots and enables traceable, reproducible and context-aware results. Traceability, reliability and reproducibility increase alongside the value delivered to R&D.
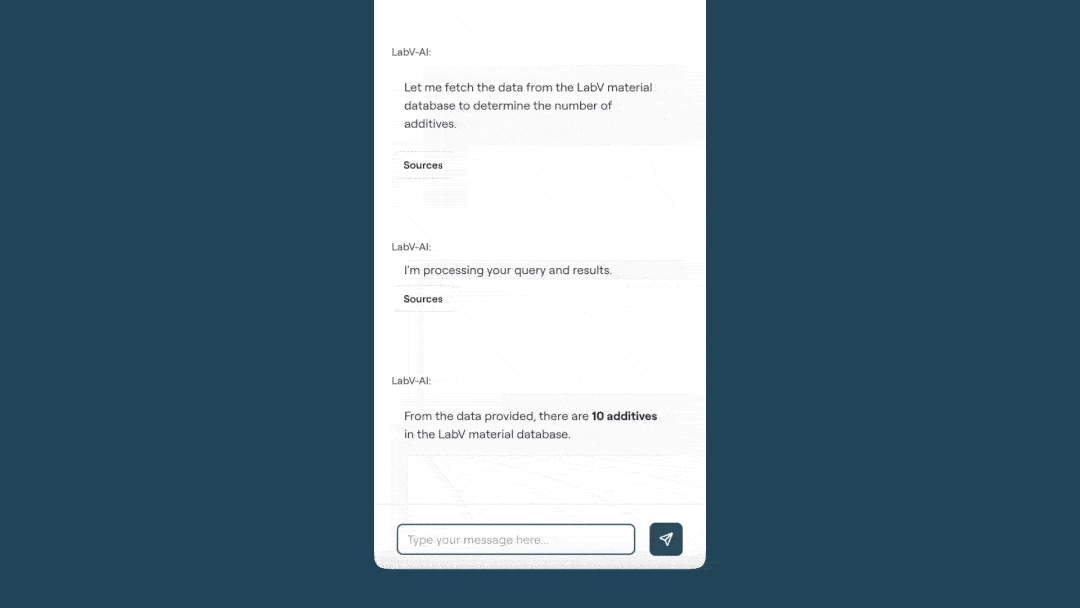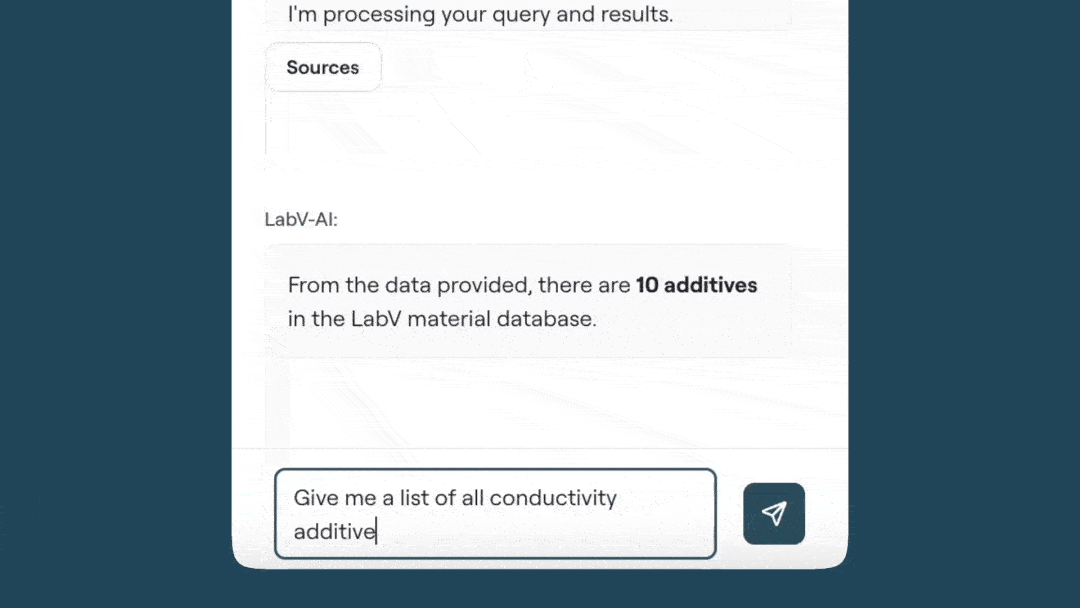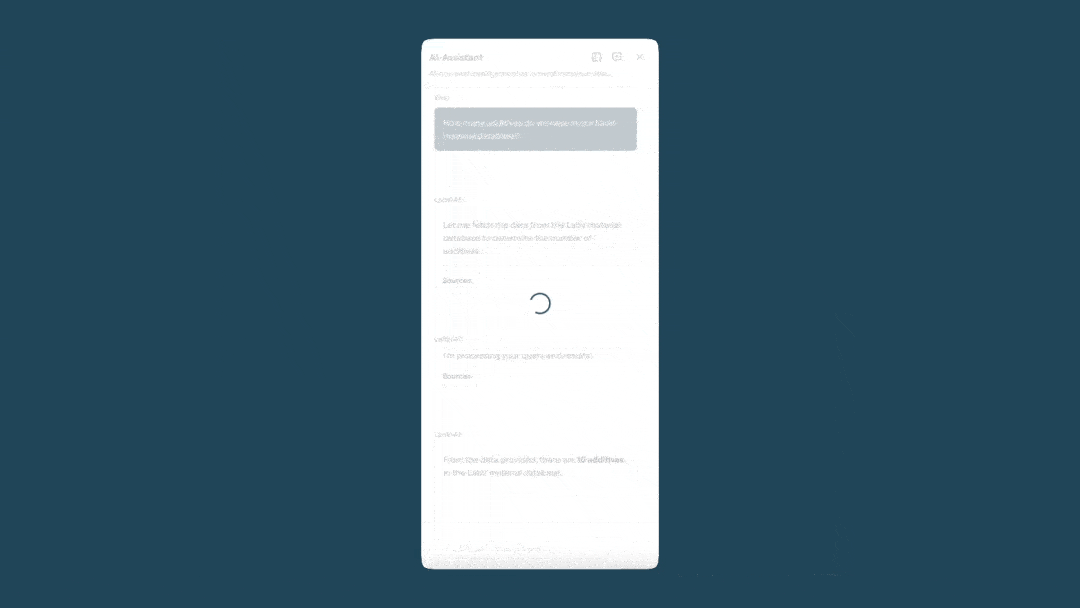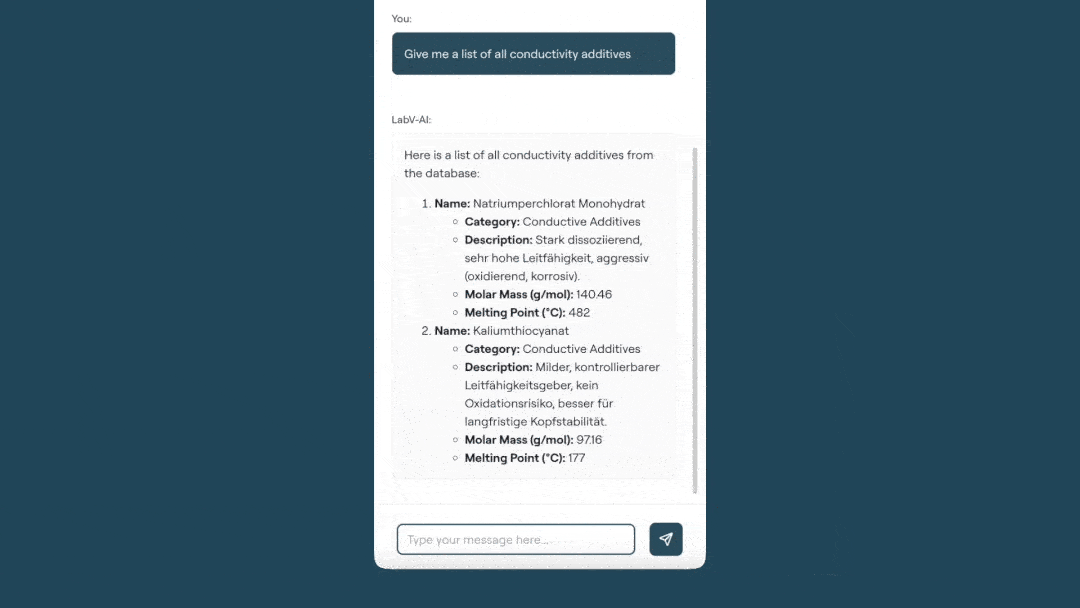
In practical use, the Co-Engineer serves as a working tool, for example in formulation development. When required, it searches the entire data base, consolidates relevant data sets and supports the identification of suitable formulation variants within defined boundary conditions (see figure below). In addition, context-relevant content from documents such as standards, specifications or test reports is provided in a targeted manner. Analyses of measurement and process data — ranging from calculations and correlations to visualisations — can be carried out directly and converted into structured summaries.
As a result, development teams spend less effort on research and analysis and make data-driven decisions rather than relying on gut feeling.
What will matter tomorrow: framework conditions for AI in R&D
Looking ahead, the next stage in the development of AI in industrial R&D will be shaped less by new features than by the framework conditions under which AI is deployed. Recent reports, such as the Gartner Technology Trends Report 2026, also point to data architecture, security and governance as increasingly decisive factors for the practical value of AI. The key question is no longer what AI can theoretically achieve, but whether organisations create the conditions required to use these capabilities reliably, securely and at scale.
This includes the establishment of trusted infrastructures. Under the term confidential computing, sensitive data is protected not only during storage or transmission, but also while it is being processed. For data-driven R&D, this is a critical aspect: AI analyses, modelling and evaluations must be able to operate on protected data without compromising confidentiality or integrity.
Another important aspect is digital provenance. R&D data represents the “crown jewels” of an organisation. Accordingly, organisations must be able to trace where data flows, how it is processed and how securely it is handled. Closely linked to this is the trend towards deliberately relocating data processing and digital value creation to regional or sovereign infrastructures — a concept known as geopatriation. The aim is to reduce geopolitical risk.
In Europe, digital sovereignty is therefore becoming a practical decision layer for industrial R&D. Data-driven research, AI-supported development and long-term innovative capacity increasingly depend on how independently companies operate their digital core systems and how they assess and select technology partnerships.
Conclusion: AI delivers value when data and context come together
Artificial intelligence is already transforming industrial R&D. However, its value is not determined by algorithms or models alone. What ultimately matters is a consistent data foundation, clearly defined workflows and the domain context in which AI is applied.
Material Intelligence provides this foundation and integrates AI-based assistance systems such as the Co-Engineer. Organisations that establish these fundamentals today will be able to use new technologies tomorrow in a secure, efficient and sovereign way — and make data-driven decisions where they create the greatest value for R&D.
FAQ: AI in industrial research and development (R&D)
What does AI mean in industrial R&D?
Artificial intelligence in industrial research and development refers to the use of algorithms and models to analyse data, generate insights and support development decisions. The value does not arise from AI alone, but from the combination of data quality, domain context and clearly defined processes.
Why do many AI projects in R&D fail?
Many AI projects fail because they are based on isolated or unstructured data sets. Without consistent data, clear attribution and contextual relevance, methods such as machine learning may produce results, but these are often too generic to be useful in day-to-day development work.
What role does data quality play for AI in R&D?
Data quality is the central prerequisite for the meaningful use of AI. What matters is consistency, comparability and contextual relevance — not sheer data volume. Only under these conditions can reliable relationships be identified and development results reused in a reproducible way.
How does an AI assistant support work in R&D?
An AI assistant supports professionals in research, analysis, comparison and decision-making. It accesses structured data and documents, establishes relationships and presents results in an understandable form. Domain responsibility always remains with the development team.
What distinguishes specialised AI systems from generic chatbots?
Specialised AI systems operate with clearly defined roles, validated data sources and domain-specific methods. Unlike generic chatbots, they deliver traceable, reproducible and context-aware results suitable for industrial R&D.
What should R&D organisations do now?
R&D organisations should first establish a consistent data foundation and clear workflows. AI can then be applied in a targeted way. Those who put structure and context in place early create the basis for scalable, secure and future-proof AI applications.
Autor: Dr Marc Egelhofer