
Zwischen Excel und KI: Warum Daten in der F&E zum Engpass werden
Jeder in der F&E kennt das Problem: Versuchsreihen, Rezepturen, Messwerte und Auswertungen landen in Excel-Tabellen. Der Kollege ergänzt seine Dokumentation durch Dateien in Ordnerstrukturen, Sharepoints oder lokalen Laufwerken. Das wird zum Problem, sobald jemand die Daten projektübergreifend nutzen, vergleichen oder über längere Zeiträume auswerten will.
Das Ergebnis: Informationen verteilen sich über verschiedene Systeme und Formate. Zuständigkeiten sind nicht klar, Bezeichnungen nicht einheitlich. Versionen lassen sich kaum nachvollziehen, Zusammenhänge zwischen Materialien, Prozessen und Ergebnissen gehen verloren. Historische Daten sind zwar vorhanden, aber nur mit erheblichem Aufwand auffindbar. Experimente werden wiederholt, die Entwicklung verzögert sich und Kunden warten.
Das ist kein theoretisches Problem. Wie eine Umfrage im Rahmen der European Coatings Fachkonferenz zur Digitalisierung zeigt, ist das Problem real: rund zwei Drittel der Teilnehmenden gaben an, dass ihre Daten schwer zugänglich oder kaum durchsuchbar sind. Ebenso viele nannten fehlende Standardisierung und eine zu hohe Anzahl unterschiedlicher Systeme als zentrale Hürde im Arbeitsalltag (Abb. 1).

Quelle: Teilnehmer der European Coatings Conference 2025
Die Suche nach relevanten Informationen hat Konsequenzen. Sie kostet die Mitarbeiter in der F&E mehr Zeit, als diese es sich leisten können. Wer keine Zeit hat, trifft Entscheidungen auf unvollständiger Datenbasis oder auf Bauchgefühl. Verlässt dann noch im Zuge eines anstehenden Generationswechsels ein erfahrener Mitarbeitender das Unternehmen, geht nicht nur dessen Wissen, sondern auch die Daten verloren. Dieser Zustand ist nicht tragfähig, denn der Wettbewerbsdruck nimmt zu und belastet Entwicklungsleiter und Teams gleichermaßen. Parallel dazu kommen neue Technologien wie künstliche Intelligenz ins Spiel, die einen Ausweg versprechen. Diese können aber nur dann ihr Potenzial entfalten, wenn strukturierte, verknüpfte und kontextualisierte Daten zur Verfügung stehen. Wie können Teams unter diesen Bedingungen fundierte Entscheidungen treffen und neue Technologien sinnvoll nutzen?
Was heute zählt: Daten strukturieren, Kontext schaffen
Die Antwort liegt weniger in einzelnen Tools als in einem strukturierten Umgang mit Daten, Prozessen und KI. Einzelne Lösungen für Datenerfassung, Projektmanagement oder Analyse greifen zu kurz. Veraltete LIMS sind zu starr, ELNs zu limitiert. Was fehlt, ist ein übergreifender Ansatz, der die Komplexität der F&E strukturiert ordnet und ein effektives Datenmanagement in der F&E ermöglicht.
Material Intelligence beschreibt genau diesen Ordnungsrahmen. Es ist kein einzelnes Tool, sondern ein Strukturprinzip für digitale Forschung und Entwicklung. Im Kern verbindet Material Intelligence drei eng miteinander verknüpfte Ebenen: Daten, Workflows und Intelligenz. Erst ihr Zusammenspiel schafft die Grundlage für effiziente Prozesse und den sinnvollen Einsatz von KI (siehe Abbildung).
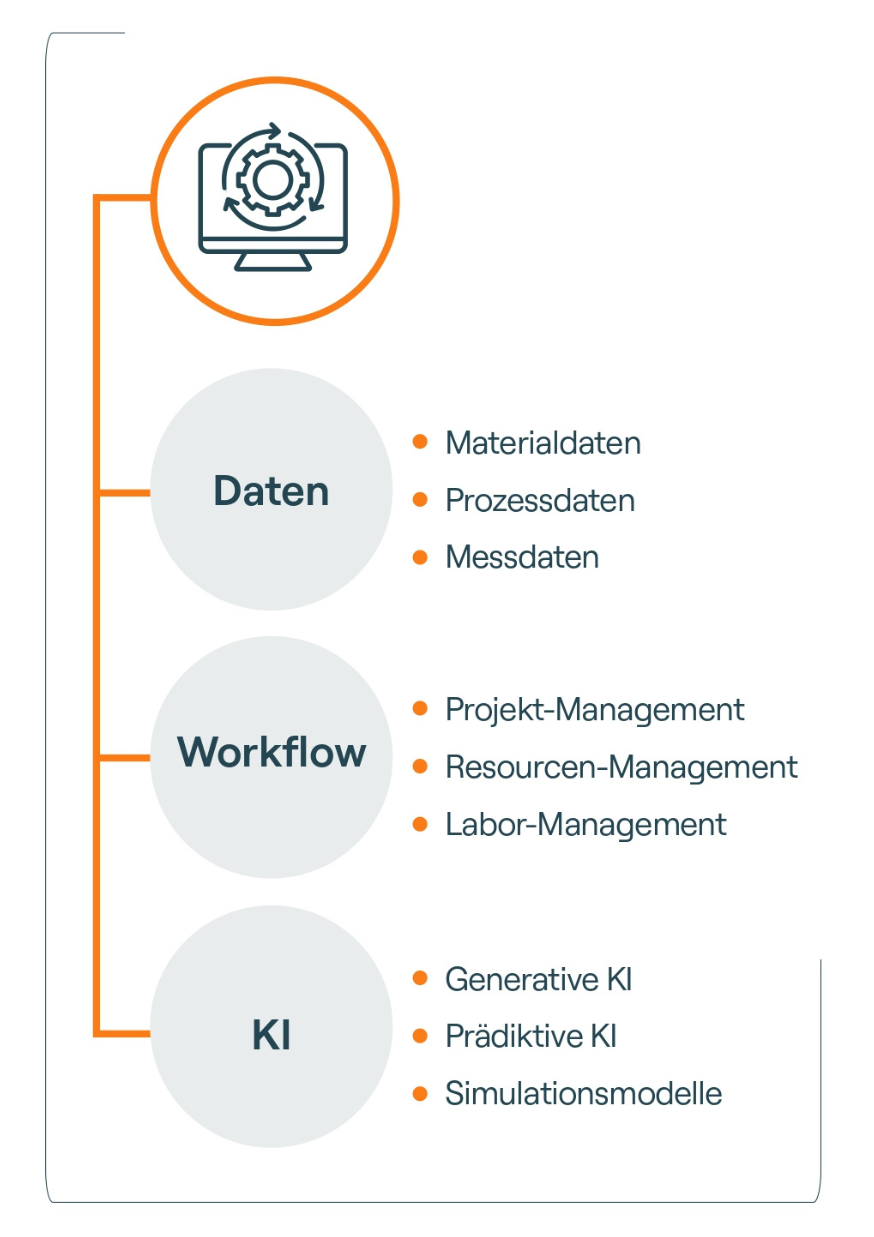
Die erste Ebene bilden strukturierte und durchsuchbare Daten – von Materialeigenschaften über Rezepturen und Prozessparameter bis hin zu Messwerten und Versuchsergebnissen. Entscheidend ist nicht die Datenmenge, sondern Konsistenz, Vergleichbarkeit und eindeutige Zuordnung. Nur so lassen sich Zusammenhänge nachvollziehen und Wissen wiederverwenden. Darauf aufbauend werden Workflows digital abgebildet und verknüpft. Projekte, Laborprozesse und Versuchsabfolgen greifen ineinander, Entscheidungen werden nachvollziehbar, Übergaben klarer. Daten entstehen nicht zufällig, sondern im Kontext ihrer Entstehung. Die dritte Ebene ist die Intelligenz. KI greift nicht isoliert auf einzelne Datensätze zu, sondern auf ein konsistentes Daten- und Prozessumfeld. Sie wird damit zu einem unterstützenden Bestandteil der täglichen Arbeit und nicht zum Fremdkörper.
Ohne strukturierte Daten bleiben Workflows lückenhaft. Ohne Workflows bleiben Daten fragmentiert. Und ohne beides kann KI keinen verlässlichen Mehrwert liefern. Material Intelligence adressiert genau diese Abhängigkeiten und reduziert Komplexität, statt sie zu erhöhen.
KI in der F&E: Vom Versprechen zur praktischen Anwendung
Die Nutzung der künstlichen Intelligenz ist in der industriellen F&E keine Vision mehr, sondern zunehmend Alltag. Gleichzeitig zeigt sich deutlich: Über Erfolg oder Misserfolg entscheidet nicht nur die Qualität der Daten, sondern auch der fachliche Kontext. In der Praxis kommen häufig KI-Assistenten als generische, kontextunabhängige Werkzeuge zum Einsatz, die mit isolierten Datensätzen arbeiten und den experimentellen Entstehungskontext nicht berücksichtigen können. Ohne die explizite Einbindung von Formulierungs-, Prozess- und Prüfinformationen liefern Verfahren wie Machine Learning aber nur allgemeine Ergebnisse. Die werden spezifischen Anforderungen in der Forschung und Entwicklung nicht gerecht. Der Nutzen im F&E-Umfeld ist so letztlich zu gering.
Das Multi-Agenten-Konzept des Co-Engineers verfolgt einen anderen Ansatz. Die Interaktion erfolgt über eine einheitliche Benutzeroberfläche, über die Anfragen an einen zentralen Supervisor-Agenten weitergegeben werden. Dieser zerlegt die Anfrage in klar definierte Teilaufgaben und koordiniert deren Bearbeitung durch spezialisierte Agenten, etwa für Suche, Analyse oder Prognose. Die einzelnen Agenten greifen dabei auf spezifische Funktionen der Tool-Schicht zurück, darunter semantische Suche, analytische und statistische Verfahren sowie prädiktive Modellierung.
Dabei kommen auch Verfahren der prädiktiven KI zum Einsatz, die auf Basis historischer Daten mögliche Ergebnisse und Trends abschätzen. Bayesian Optimization ergänzt diesen Ansatz, indem sie gezielt neue Versuche vorschlägt, die den Erkenntnisgewinn maximieren und den experimentellen Aufwand reduzieren.
Alle Tools arbeiten auf einer gemeinsamen Daten- und Infrastruktur, die Labordaten aus der Datenbank sowie zugehörige Dokumentenbestände umfasst. Durch diese klare Aufgabentrennung und den Einsatz domänenspezifischer Methoden unterscheidet sich der Co-Engineer grundlegend von generischen Chatbots und liefert nachvollziehbare, reproduzierbare und kontextbezogene Ergebnisse. Nachvollziehbarkeit, Zuverlässigkeit und Reproduzierbarkeit steigen gemeinsam mit dem Nutzen für die F&E.
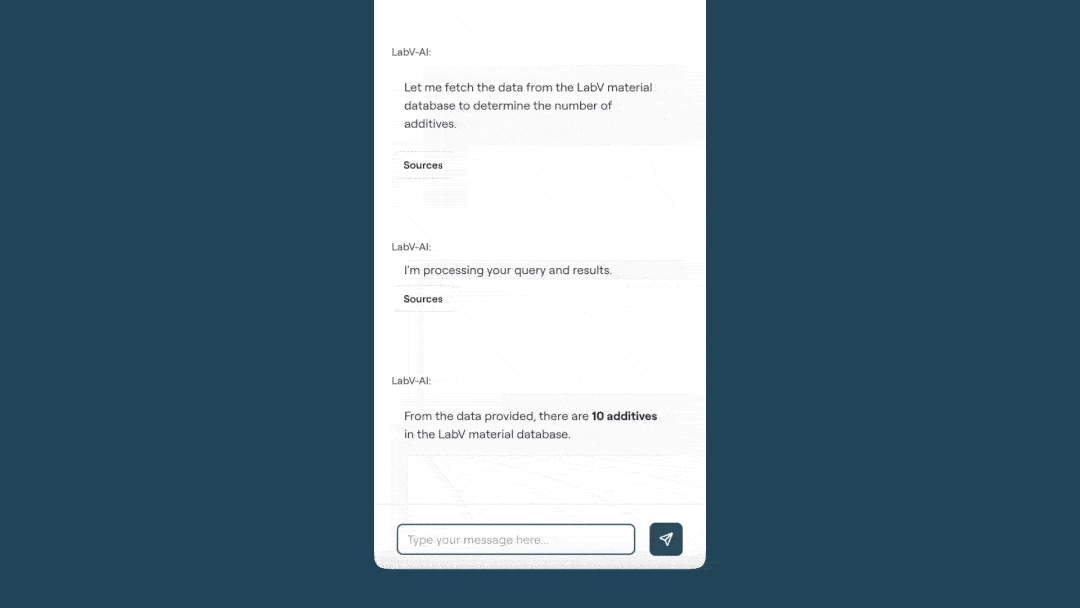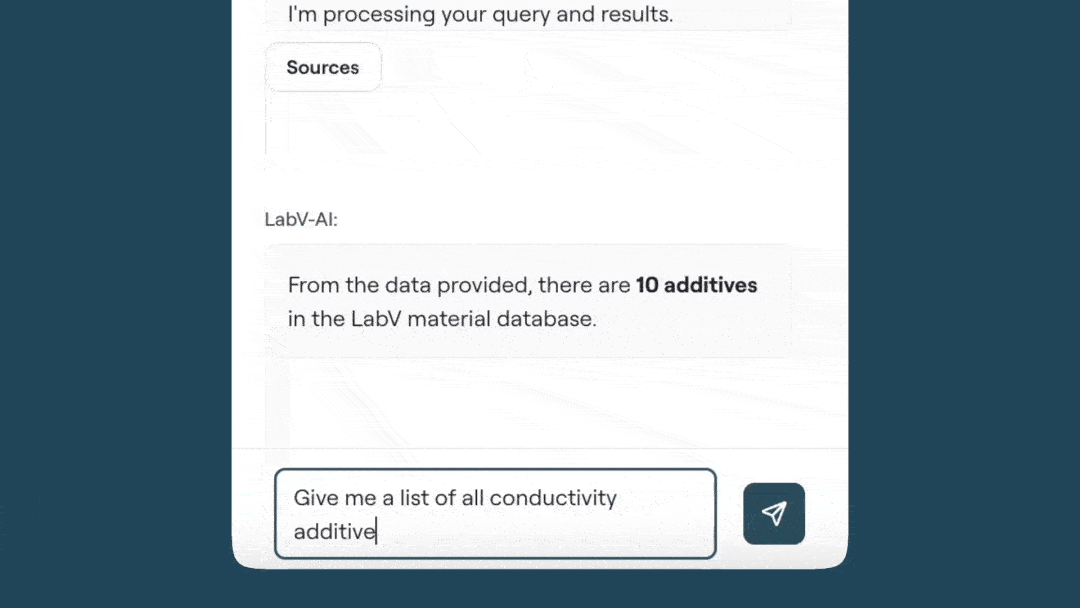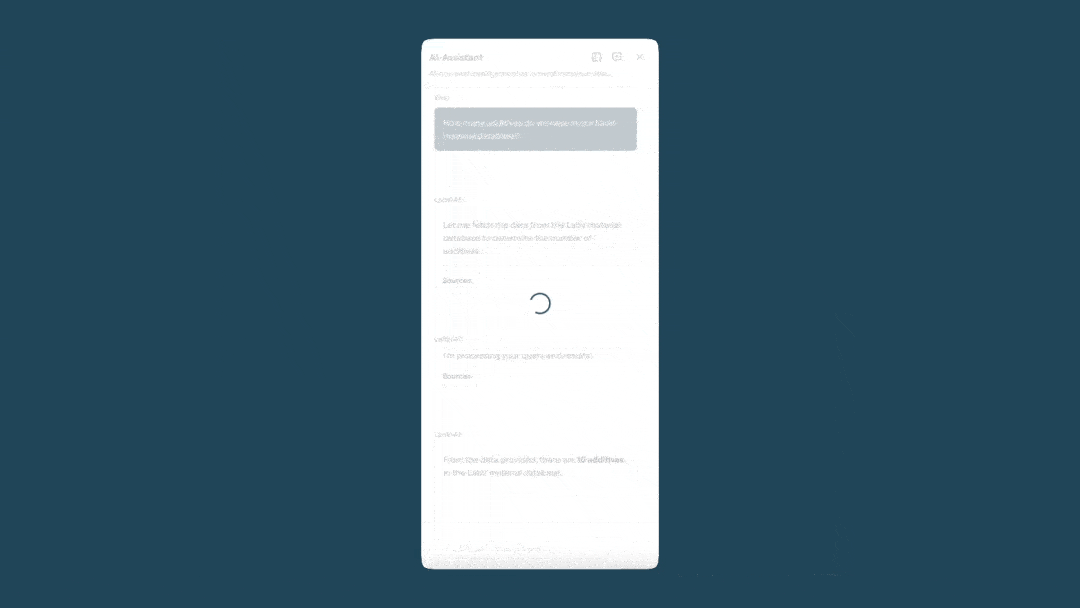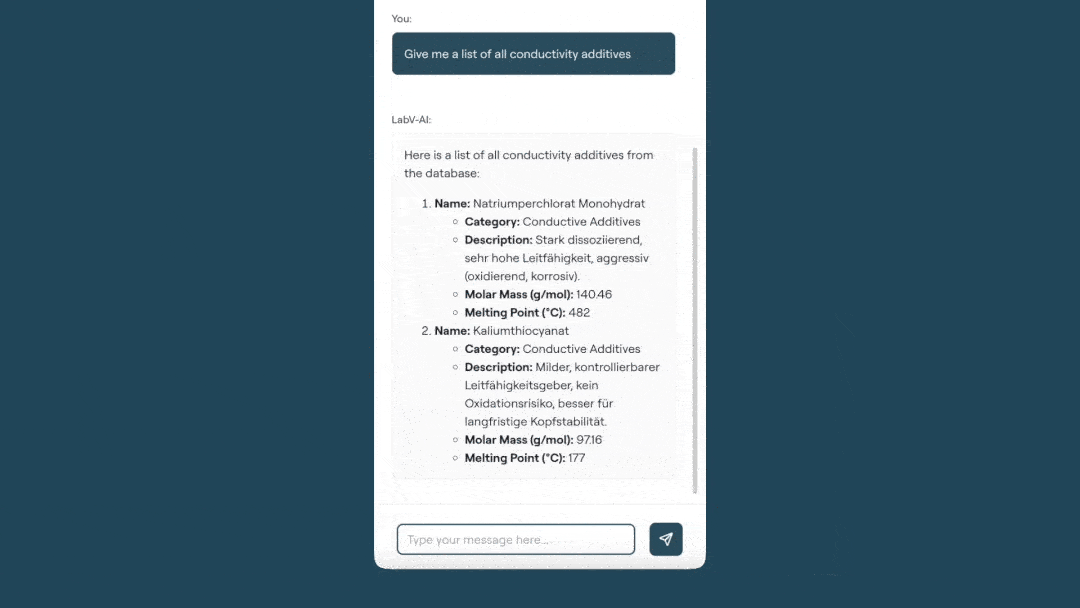
Im praktischen Einsatz dient der Co-Engineer als Arbeitswerkzeug, beispielsweise in der Formulierungsentwicklung. Er durchsucht bei Bedarf die gesamte Datenbasis, konsolidiert relevante Datensätze und unterstützt bei der Identifikation geeigneter Rezepturvarianten innerhalb definierter Randbedingungen S8eieh Abbildung unten). Ergänzend werden kontextrelevante Inhalte aus Dokumenten wie Normen, Spezifikationen oder Prüfberichten gezielt bereitgestellt. Analysen auf Mess- und Prozessdaten – von Berechnungen über Korrelationen bis hin zu Visualisierungen – lassen sich direkt durchführen und in strukturierte Zusammenfassungen überführen. Das Entwicklerteam benötigt mit dem KI-Assistenten so weniger Aufwand für seine Recherchen und Auswertungen und trifft datenbasierte Entscheidungen statt Bauchgefühl.
Was morgen entscheidet: Rahmenbedingungen für KI in der F&E
Der Blick nach vorne zeigt: Der nächste Entwicklungsschritt von KI in der industriellen F&E wird weniger durch neue Funktionen bestimmt als durch die Rahmenbedingungen, unter denen KI eingesetzt wird. Auch aktuelle Berichte wie der Gartner-Trendbericht 2026 weisen darauf hin, dass Themen wie Datenarchitektur, Sicherheit und Governance zunehmend über den praktischen Nutzen von KI entscheiden. Es geht nicht darum, was KI theoretisch leisten kann, sondern ob Organisationen die Voraussetzungen schaffen, um diese Fähigkeiten zuverlässig, sicher und skalierbar zu nutzen.
Dazu gehört der Aufbau vertrauenswürdiger Infrastrukturen. Unter dem Stichwort Confidential Computing geht es darum, sensible Daten nicht nur bei der Speicherung oder Übertragung zu schützen, sondern auch während ihrer Verarbeitung. Für die datengetriebene F&E ist dies ein entscheidender Punkt: KI-Analysen, Modellierungen und Auswertungen müssen auf geschützten Daten arbeiten können, ohne dass deren Vertraulichkeit oder Integrität gefährdet wird.
Wichtiger Aspekt: Die digitale Herkunft. F&E-Daten zählen zu den „Kronjuwelen“ eines Unternehmens. Entsprechend müssen Organisationen nachvollziehen können, wohin Daten fließen, wie sie verarbeitet werden und wie sicher dieser Umgang ist. Eng damit verbunden ist der Trend die bewusste Verlagerung von Datenverarbeitung und digitaler Wertschöpfung in regionale oder souveräne Infrastrukturen – die Geopatriation. Sie soll geopolitische Risiken reduzieren. Die Digitale Souveränität wird in Europa damit zur praktischen Entscheidungsebene für industrielle F&E. Datenbasierte Forschung, KI-gestützte Entwicklung und langfristige Innovationsfähigkeit hängen davon ab, wie unabhängig Unternehmen ihre digitalen Kernsysteme betreiben und Technologiepartnerschaften entsprechend bewerten.
Fazit: KI entfaltet ihren Nutzen wenn Daten und Kontext zusammenkommen
Künstliche Intelligenz verändert die industrielle F&E bereits heute. Ihr Nutzen entscheidet sich jedoch nicht in Algorithmen oder Modellen. Ausschlaggebend sind eine konsistente Datenbasis, klar definierte Workflows und der fachliche Kontext, in dem KI eingesetzt wird. Material Intelligence schafft dafür die notwendige Basis und integriert KI-gestützte Assistenzsysteme wie den Co-Engineer. Wer diese Grundlagen heute legt, kann neue Technologien morgen sicher, effizient und souverän nutzen und datenbasierte Entscheidungen dort treffen, wo sie für die F&E den größten Mehrwert bringen.
FAQ: KI in der industriellen Forschung und Entwicklung (F&E)
Was bedeutet KI in der industriellen F&E?
Künstliche Intelligenz in der industriellen Forschung und Entwicklung beschreibt den Einsatz von Algorithmen und Modellen zur Analyse, Auswertung und Unterstützung von Entwicklungsentscheidungen. Der Mehrwert entsteht nicht durch KI allein, sondern durch die Kombination aus Datenqualität, fachlichem Kontext und klaren Prozessen.
Warum scheitern viele KI-Projekte in der F&E?
Viele KI-Projekte scheitern, weil sie auf isolierten oder unstrukturierten Datensätzen basieren. Ohne konsistente Daten, eindeutige Zuordnung und Kontextbezug liefern Verfahren wie Machine Learning zwar Ergebnisse, diese sind jedoch oft zu allgemein und für den Entwicklungsalltag kaum nutzbar.
Welche Rolle spielt Datenqualität für KI in der F&E?
Datenqualität ist die zentrale Voraussetzung für den sinnvollen Einsatz von KI. Entscheidend sind Konsistenz, Vergleichbarkeit und Kontextbezug – nicht die reine Datenmenge. Nur so lassen sich belastbare Zusammenhänge erkennen und Entwicklungsergebnisse reproduzierbar nutzen.
Wie unterstützt ein KI-Assistent die Arbeit in der F&E?
Ein KI-Assistent unterstützt Fachkräfte bei Recherche, Analyse, Vergleich und Entscheidungsfindung. Er greift auf strukturierte Daten und Dokumente zu, stellt Zusammenhänge her und bereitet Ergebnisse verständlich auf. Die fachliche Verantwortung bleibt dabei stets beim Entwicklungsteam.
Was unterscheidet spezialisierte KI-Systeme von generischen Chatbots?
Spezialisierte KI-Systeme arbeiten mit klar definierten Rollen, validierten Datenquellen und domänenspezifischen Methoden. Im Gegensatz zu generischen Chatbots liefern sie nachvollziehbare, reproduzierbare und kontextbezogene Ergebnisse, die für industrielle F&E geeignet sind.
Was sollten F&E-Organisationen jetzt konkret tun?
F&E-Organisationen sollten zuerst eine konsistente Datenbasis und klare Workflows schaffen. Darauf aufbauend lässt sich KI gezielt einsetzen. Wer Struktur und Kontext frühzeitig etabliert, schafft die Grundlage für skalierbare, sichere und zukunftsfähige KI-Anwendungen.
Autor: Dr Marc Egelhofer